机器学习是一个巨大的学科,其应用范围从自然语言处理到求解偏微分方程。正是从这个领域中,诞生了像 PyTorch、TensorFlow 和 Flux.jl 这样的主要框架,并努力成为“所有机器学习”的包。虽然其中一些框架得到了 Facebook 和 Google 等大型公司的支持,但 Julia 社区依赖于 Julia 编程语言本身的速度和生产力,以便其开源社区跟上发展步伐。正是从这个角度,Flux.jl 衍生出其“精简性”:虽然 PyTorch 和 TensorFlow 包含完整的独立语言和编译器(torchscript、XLA 等),但 Flux.jl 只是 Julia。正是从这一点上,Flux.jl 通常被称为“你可以自己构建它”。
在这篇文章中,我们从不同的角度来看待 Julia 的可编程性如何在机器学习领域发挥作用。具体来说,通过瞄准“所有机器学习”的广阔空间,框架不可避免地会做出一些权衡,以加速代码的某些方面,而牺牲其他方面。这是来自简单性、通用性和性能之间不可避免的权衡。但是,轻松构建机器学习库的能力带来了一个有趣的问题:这种开发功能可以用来轻松创建将性能集中在更多非传统应用或方面上的替代框架吗?
答案是肯定的,您可以使用 Julia 编程语言快速构建机器学习实现,这些实现能够在特定情况下大大超过框架,我们通过我们的新软件包来演示这一点:SimpleChains.jl。
科学机器学习 (SciML) 和“小型”神经网络
SimpleChains.jl 是一个由 Pumas-AI 和 JuliaHub 联合开发的库,与 罗氏 和 马里兰大学巴尔的摩分校 合作开发。SimpleChains.jl 的目的是对小型神经网络尽可能快。SimpleChains.jl 起源于 Pumas-AI 的 DeepPumas 产品的解决方案,用于 医疗保健数据分析中的科学机器学习 (SciML)。例如,小型神经网络(和其他逼近器,例如傅里叶级数或切比雪夫多项式展开)可以与已知的半生理模型结合,以发现以前未知的机制和预后因素。有关如何做到这一点的简要介绍,请查看 Niklas Korsbo 的以下视频
这种 SciML 方法 已在许多学科中得到证明,从黑洞动力学到抗震建筑物的开发,它是一种灵活的方法,能够发现/指导(生物)物理方程。以下是一个最近的演讲,介绍了 SciML 在整个科学领域中的各种用例
有关软件和方法的更多详细信息,请参阅我们关于科学机器学习通用微分方程的论文。
神经网络在这些上下文中的使用方式的独特方面,使其成为通过专门化进行性能改进的绝佳选择。具体来说,在机器学习的背景下,人们通常依赖于以下假设:神经网络足够大,以至于矩阵-矩阵乘法 (O(n^3)) 的成本(或其他内核,如卷积)支配着运行时。这实际上是大多数机器学习库机制背后的指导原则
矩阵-矩阵乘法呈立方增长,而内存分配呈线性增长,因此尝试使用非分配操作来改变向量不是一个优先事项。只需使用
A*x即可。专注于尽可能快地加速 GPU 内核!由于这些大型矩阵-矩阵操作在 GPU 上速度最快,并且是瓶颈,因此性能基准测试本质上只是对这些特定内核速度的测量。
在进行反向模式自动微分(反向传播)时,可以随意将值复制到内存中。内存分配将被更大的内核调用隐藏。
此外,可以随意为生成反向传播编写一个“磁带”。磁带确实增加了在正向传递过程中构建字典的成本,但这将被更大的内核调用隐藏。
这些假设在我们案例中是否真的成立?如果它们不成立,我们可以专注于这些方面,以便为我们的用例获得更多性能?
深入探讨:小型神经网络性能开销
当我们开始关注这种更小的神经网络用例时,很容易证明这些假设会失效。首先,让我们看看假设 (1)(2)。显示这两个假设在哪里失效并不难
using LinearAlgebra, BenchmarkTools, CUDA, LoopVectorization
function mygemmturbo!(C, A, B)
@tturbo for m ∈ axes(A, 1), n ∈ axes(B, 2)
Cmn = zero(eltype(C))
for k ∈ axes(A, 2)
Cmn += A[m, k] * B[k, n]
end
C[m, n] = Cmn
end
end
function alloc_timer(n)
A = rand(Float32,n,n)
B = rand(Float32,n,n)
C = rand(Float32,n,n)
t1 = @belapsed $A * $B
t2 = @belapsed (mul!($C,$A,$B))
t3 = @belapsed (mygemmturbo!($C,$A,$B))
A,B,C = (cu(A), cu(B), cu(C))
t4 = @belapsed CUDA.@sync($A * $B)
t5 = @belapsed CUDA.@sync(mul!($C,$A,$B))
t1,t2,t3,t4,t5
end
ns = 2 .^ (2:11)
res = [alloc_timer(n) for n in ns]
alloc = [t[1] for t in res]
noalloc = [t[2] for t in res]
noalloclv = [t[3] for t in res]
allocgpu = [t[4] for t in res]
noallocgpu = [t[5] for t in res]
using Plots
plot(ns, alloc, label="*", xscale=:log10, yscale=:log10, legend=:bottomright,
title="Which Micro-optimizations matter for BLAS3?",
yticks=10.0 .^ (-8:0.5:2),
ylabel="Time (s)", xlabel="N",)
plot!(ns,noalloc,label="mul! (OpenBLAS)")
plot!(ns,noalloclv,label="mygemmturbo!")
plot!(ns,allocgpu,label="* gpu")
plot!(ns,noallocgpu,label="mul! gpu")
savefig("microopts_blas3.png")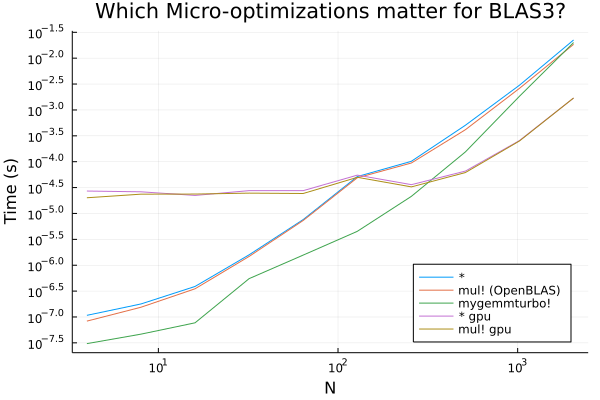
当我们进行更大的矩阵-矩阵操作(例如 100x100 * 100x100)时,我们可以有效地忽略由于内存分配造成的任何开销。但我们确实看到了在低端领域存在一些相当可观的性能提升的可能性!注意,这些收益是通过使用纯 Julia LoopVectorization.jl 作为标准 BLAS 工具来实现的,因为这些工具在这个区域往往会产生额外的线程开销(同样,在这个区域没有进行很多优化)。
如果您一直沉浸在 GPU 的福音中而没有深入研究细节,那么这个图可能会让您感到震惊!但是,GPU 被设计为具有许多内核的笨拙的慢速芯片,因此它们仅对非常并行的操作(如大型矩阵-矩阵乘法)有效。正是从这一点,假设 (2) 针对大型网络操作而得出。但同样,在小型网络的情况下,由于缺乏并行机会,这些 GPU 内核的性能将低于设计良好的 CPU 内核。
矩阵-矩阵操作仅在能够使用批处理时发生(其中 B 矩阵中的每一列在 A*B 中都是一个单独的批处理)。在许多科学机器学习的情况下,例如 ODE 伴随中的向量-雅可比积的计算,此操作是一个矩阵-向量乘法。这些操作较小,仅为 O(n^2),并且如您所料,这些影响在这种情况下会放大
using LinearAlgebra, BenchmarkTools, CUDA, LoopVectorization
function mygemmturbo!(C, A, B)
@tturbo for m ∈ axes(A, 1), n ∈ axes(B, 2)
Cmn = zero(eltype(C))
for k ∈ axes(A, 2)
Cmn += A[m, k] * B[k, n]
end
C[m, n] = Cmn
end
end
function alloc_timer(n)
A = rand(Float32,n,n)
B = rand(Float32,n)
C = rand(Float32,n)
t1 = @belapsed $A * $B
t2 = @belapsed (mul!($C,$A,$B))
t3 = @belapsed (mygemmturbo!($C,$A,$B))
A,B,C = (cu(A), cu(B), cu(C))
t4 = @belapsed CUDA.@sync($A * $B)
t5 = @belapsed CUDA.@sync(mul!($C,$A,$B))
t1,t2,t3,t4,t5
end
ns = 2 .^ (2:11)
res = [alloc_timer(n) for n in ns]
alloc = [t[1] for t in res]
noalloc = [t[2] for t in res]
noalloclv = [t[3] for t in res]
allocgpu = [t[4] for t in res]
noallocgpu = [t[5] for t in res]
using Plots
plot(ns, alloc, label="* (OpenBLAS)", xscale=:log10, yscale=:log10, legend=:bottomright,
title="Which Micro-optimizations matter for BLAS2?",
yticks=10.0 .^ (-8:0.5:2),
ylabel="Time (s)", xlabel="N",)
plot!(ns,noalloc,label="mul! (OpenBLAS)")
plot!(ns,noalloclv,label="mygemvturbo!")
plot!(ns,allocgpu,label="* gpu")
plot!(ns,noallocgpu,label="mul! gpu")
savefig("microopts_blas2.png")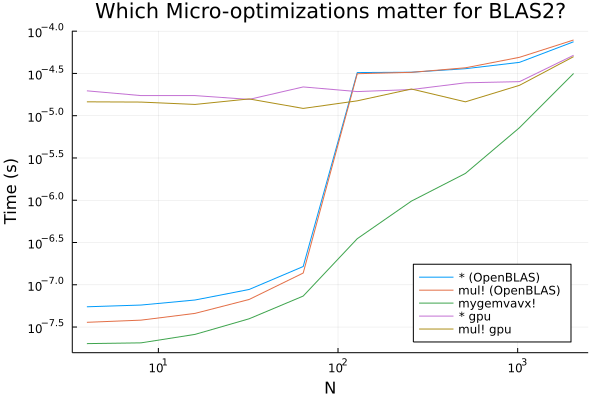
请记住,神经网络的基本操作是 sigma.(W*x .+ b),因此也存在一个 O(n) 元素级操作。如您所料,随着 n 变小,此操作变得更加重要,同时需要更加注意内存操作。
using LinearAlgebra, BenchmarkTools, CUDA, LoopVectorization
function mybroadcastturbo!(C, A, B)
@tturbo for k ∈ axes(A, 2)
C[k] += A[k] * B[k]
end
end
function alloc_timer(n)
A = rand(Float32,n,n)
B = rand(Float32,n,n)
C = rand(Float32,n,n)
t1 = @belapsed $A .* $B
t2 = @belapsed ($C .= $A .* $B)
t3 = @belapsed (mybroadcastturbo!($C, $A, $B))
A,B,C = (cu(A), cu(B), cu(C))
t4 = @belapsed CUDA.@sync($A .* $B)
t5 = @belapsed CUDA.@sync($C .= $A .* $B)
t1,t2,t3,t4,t5
end
ns = 2 .^ (2:11)
res = [alloc_timer(n) for n in ns]
alloc = [t[1] for t in res]
noalloc = [t[2] for t in res]
noalloclv = [t[3] for t in res]
allocgpu = [t[4] for t in res]
noallocgpu = [t[5] for t in res]
using Plots
plot(ns,alloc,label="=",xscale=:log10,yscale=:log10,legend=:bottomright,
title="Which Micro-optimizations matter for BLAS1?",
ylabel = "Time (s)", xlabel = "N",
yticks = 10.0 .^ (-8:0.5:2),)
plot!(ns,noalloc,label=".=")
plot!(ns, noalloc, label="mybroadcastturbo!")
plot!(ns,allocgpu,label="= gpu")
plot!(ns,noallocgpu,label=".= gpu")
savefig("microopts_blas1.png")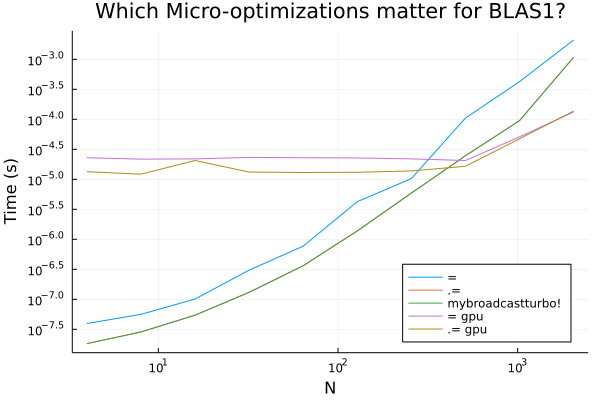
这已经极大地激励了一个专注于此案例性能的项目,但假设 (3) 和 (4) 指示我们另外关注反向传播的实现。 不同的机器学习库对自动微分方法的权衡已经得到了充分的讨论,但一般讨论可能会忽略的是,当真正专门针对某个领域时,能够获得更多机会。例如,考虑在神经常微分方程 (neural ODE) 和 ODE 伴随内部的用例。如上所述,在此用例中,反向传递紧随正向传递之后立即应用。因此,虽然 神经网络层的手写伴随 可能看起来像
ZygoteRules.@adjoint function (f::FastDense)(x,p)
W = ...
b = ...
r = W*x .+ b
y = f.σ.(r)
function FastDense_adjoint(v)
σbar = ForwardDiff.derivative.(f.σ,r)
zbar = v .* σbar
Wbar = zbar * x'
bbar = zbar
xbar = W' * zbar
nothing,xbar,vcat(vec(Wbar),bbar)
end
y,FastDense_adjoint
end对于 sigma.(W*x .+ b) 来计算 J'v,如果您知道反向传递将紧随正向传递之后立即进行,那么您可以对此进行极大的优化。具体来说,无需生成闭包来存储值,因为将来没有不确定的时间需要梯度,而是可以直接进行计算。并且,如果您仅将其应用于已知大小为 v 的向量,那么此操作可以通过改变缓存向量来完成而无需分配。最后,如果我们知道我们只将使用关于 x (xbar) 的导数,那么我们可以消除许多计算。请查看简化版本
r = W*x .+ b
y = σ.(r)
σbar = derivative.(σ,r)
zbar = v .* σbar
Wbar = zbar * x'
bbar = zbar
xbar = W' * zbar现在已缓存
mul!(cache,W,x)
cache .= σ.(cache .+ b)
cache .= derivative.(σ,cache)
cache .= v .* cache
mul!(xbar,W',cache)或者换句话说,我们可以将其写为具有单个缓存向量的改变操作:vjp!(xbar,W,b,σ,v,cache)。所有自动微分或改变的开销?都不见了。
当然,为除最简单情况以外的任何其他情况构建它都需要更大的努力。SimpleChains.jl 应运而生。
SimpleChains.jl:一个针对 SciML 用例优化的机器学习库
SimpleChains.jl 是解决这个问题的方案。SimpleChains.jl 是一个小型机器学习框架,针对在 CPU 上快速拟合小型模型进行了优化。早期的开发更倾向于一种设计,该设计将
使我们能够获得良好的性能,理想情况下接近 CPU 的潜在峰值 FLOPs。
专注于小尺寸意味着我们可以在开发初期阶段基本上放弃大型内核优化(如缓存平铺)。
具有一个 API,其中参数向量(及其梯度)是第一类,而不是让参数与层一起存在,以便更容易使用期望连续向量(例如 BFGS)的各种优化器或求解器。
用“纯 Julia”编写,以方便开发和优化;虽然大量使用 LoopVectorization.jl,但 SimpleChains.jl 不依赖任何 BLAS 或 NN 库。长期目标是将这种循环编译器方法扩展到优化,从而自动生成拉回,而无需手动编写。但是,以编译器为中心的这种方法已经用于简化实现:虽然我们仍然需要手动编写梯度,但我们不需要手动优化它们。
SimpleChains.jl 实战:在微型示例中将 PyTorch 提高 30 倍
注意:所有显示的代码都使用 SimpleChains v0.2.2。有关更新,请参阅 该软件包的文档
首先让我们尝试一个微型示例,我们将一个 2x2 矩阵映射到其矩阵指数;我们的训练和测试数据
function f(x)
N = Base.isqrt(length(x))
A = reshape(view(x, 1:N*N), (N,N))
expA = exp(A)
vec(expA)
end
T = Float32;
D = 2 # 2x2 matrices
X = randn(T, D*D, 10_000); # random input matrices
Y = reduce(hcat, map(f, eachcol(X))); # `mapreduce` is not optimized for `hcat`, but `reduce` is
Xtest = randn(T, D*D, 10_000);
Ytest = reduce(hcat, map(f, eachcol(Xtest)));要拟合它,我们定义以下模型
using SimpleChains
mlpd = SimpleChain(
static(4),
TurboDense(tanh, 32),
TurboDense(tanh, 16),
TurboDense(identity, 4)
)第一层将 4 维输入映射到 32 维,使用密集(线性)层,应用非线性 tanh 激活。第二层将这些 32 个输出映射到 16 维,使用另一个密集层,再次应用元素级的 tanh,然后是最终层的密集层将这些映射到 4 维结果,我们可以将其重塑为 2x2 矩阵,希望它近似等于指数。
我们可以像下面这样拟合这个矩阵
@time p = SimpleChains.init_params(mlpd);
G = SimpleChains.alloc_threaded_grad(mlpd);
mlpdloss = SimpleChains.add_loss(mlpd, SquaredLoss(Y));
mlpdtest = SimpleChains.add_loss(mlpd, SquaredLoss(Ytest));
report = let mtrain = mlpdloss, X=X, Xtest=Xtest, mtest = mlpdtest
p -> begin
let train = mlpdloss(X, p), test = mlpdtest(Xtest, p)
@info "Loss:" train test
end
end
end
report(p)
for _ in 1:3
@time SimpleChains.train_unbatched!(
G, p, mlpdloss, X, SimpleChains.ADAM(), 10_000
);
report(p)
end在 Intel i9 10980XE 上,一个 18 核系统,具有 AVX512 和两个 512 位 fma 单元/核,这将产生
julia> report(p)
┌ Info: Loss:
│ train = 13.402281f0
└ test = 14.104155f0
julia> for _ in 1:3
# fit with ADAM for 10_000 epochs
@time SimpleChains.train_unbatched!(
G, p, mlpdloss, X, SimpleChains.ADAM(), 10_000
);
report(p)
end
4.851989 seconds (13.06 M allocations: 687.553 MiB, 10.57% gc time, 89.65% compilation time)
┌ Info: Loss:
│ train = 0.015274665f0
└ test = 0.14084631f0
0.416341 seconds
┌ Info: Loss:
│ train = 0.0027618674f0
└ test = 0.09321652f0
0.412371 seconds
┌ Info: Loss:
│ train = 0.0016900344f0
└ test = 0.08270371f0这在一个新的会话中运行,因此 train_unbatched 的第一次运行包含编译时间。一旦它编译完成,每批 10_000 次迭代只需 0.41 秒多一点,或者大约 41 微秒/迭代。
我们还有一个 PyTorch 模型 在这里 用于拟合它,它产生了
Initial Train Loss: 7.4430
Initial Test Loss: 7.3570
Took: 15.28 seconds
Train Loss: 0.0051
Test Loss: 0.0421
Took: 15.22 seconds
Train Loss: 0.0015
Test Loss: 0.0255
Took: 15.25 seconds
Train Loss: 0.0008
Test Loss: 0.0213耗时超过 35 倍,大约 1.5 毫秒/迭代。
尝试在 AMD EPYC 7513,32 核 CPU 上运行,该 CPU 具有 AVX2
julia> report(p)
┌ Info: Loss:
│ train = 11.945223f0
└ test = 12.403147f0
julia> for _ in 1:3
@time SimpleChains.train_unbatched!(
G, p, mlpdloss, X, SimpleChains.ADAM(), 10_000
);
report(p)
end
5.214252 seconds (8.85 M allocations: 581.803 MiB, 4.73% gc time, 84.76% compilation time)
┌ Info: Loss:
│ train = 0.016855776f0
└ test = 0.06515023f0
0.717071 seconds
┌ Info: Loss:
│ train = 0.0027835001f0
└ test = 0.036451153f0
0.726994 seconds
┌ Info: Loss:
│ train = 0.0017783737f0
└ test = 0.02649088f0而 PyTorch 实现则得到
Initial Train Loss: 6.9856
Initial Test Loss: 7.1151
Took: 69.46 seconds
Train Loss: 0.0094
Test Loss: 0.0097
Took: 73.68 seconds
Train Loss: 0.0010
Test Loss: 0.0056
Took: 68.02 seconds
Train Loss: 0.0006
Test Loss: 0.0039SimpleChains 在此系统上针对此模型的优势接近 100 倍。
这样的小模型是开发 SimpleChains 的动机。但是,随着我们增加问题规模,当 GPU 传统上开始性能超过 CPU 时,它的表现如何呢?
编辑:与 Jax 的计时比较
Jax Equinox 库的作者提交了 Jax 代码用于基准测试。在 AMD Ryzen 9 5950X 16 核处理器上,我们看到 Jax 的结果为
Took: 14.52 seconds
Train Loss: 0.0304
Test Loss: 0.0268
Took: 14.00 seconds
Train Loss: 0.0033
Test Loss: 0.0154
Took: 13.85 seconds
Train Loss: 0.0018
Test Loss: 0.0112而 SimpleChains.jl 使用 16 个线程的结果为
5.097569 seconds (14.81 M allocations: 798.000 MiB, 3.94% gc time, 73.62% compilation time)
┌ Info: Loss:
│ train = 0.022585187f0
└ test = 0.32509857f0
1.310997 seconds
┌ Info: Loss:
│ train = 0.0038023277f0
└ test = 0.23108596f0
1.295088 seconds
┌ Info: Loss:
│ train = 0.0023415526f0
└ test = 0.20991518f0或者性能提高了 10 倍。在 36 × Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz 上,我们看到 Jax 的结果为
Initial Train Loss: 6.4232
Initial Test Loss: 6.1088
Took: 9.26 seconds
Train Loss: 0.0304
Test Loss: 0.0268
Took: 8.98 seconds
Train Loss: 0.0036
Test Loss: 0.0156
Took: 9.01 seconds
Train Loss: 0.0018
Test Loss: 0.0111而 SimpleChains.jl 的结果为
4.810973 seconds (13.03 M allocations: 686.357 MiB, 8.25% gc time, 89.76% compilation time)
┌ Info: Loss:
│ train = 0.011851382f0
└ test = 0.017254675f0
0.410168 seconds
┌ Info: Loss:
│ train = 0.0037487738f0
└ test = 0.009099905f0
0.410368 seconds
┌ Info: Loss:
│ train = 0.002041543f0
└ test = 0.0065089874f0或者速度提高了约 22 倍。在未知的 6 核 CPU 上,线程数未知,我们看到 Jax 的结果为
Initial Train Loss: 6.4232
Initial Test Loss: 6.1088
Took: 19.39 seconds
Train Loss: 0.0307
Test Loss: 0.0270
Took: 18.91 seconds
Train Loss: 0.0037
Test Loss: 0.0157
Took: 20.09 seconds
Train Loss: 0.0018
Test Loss: 0.0111而 SimpleChains.jl 的结果为
13.428804 seconds (17.76 M allocations: 949.815 MiB, 2.89% gc time, 100.00% compilation time)
┌ Info: Loss:
│ train = 12.414271f0
└ test = 12.085746f0
17.685621 seconds (14.99 M allocations: 808.462 MiB, 4.02% gc time, 48.56% compilation time)
┌ Info: Loss:
│ train = 0.034923762f0
└ test = 0.052024134f0
9.208631 seconds (19 allocations: 608 bytes)
┌ Info: Loss:
│ train = 0.0045825513f0
└ test = 0.03521506f0
9.258355 seconds (30 allocations: 960 bytes)
┌ Info: Loss:
│ train = 0.0026099205f0
└ test = 0.023117168f0因此,针对 Jax,我们看到了 2x-22x 的性能提升,性能提升幅度随着线程可用性和 AVX512 的存在而增加。更多细节可以在 此链接 中找到,我们也邀请其他人更详细地对这些库进行基准测试并分享结果。
SimpleChains.jl 在行动:在小型示例中将 PyTorch 速度提升 5 倍
让我们使用 LeNet5 测试 MNIST。请注意,此示例将对速度进行非常保守的估计,因为作为一个更传统的机器学习用例,可以利用批处理来使用矩阵-矩阵乘法而不是更小的矩阵-向量内核。也就是说,即使在这种情况下,我们也能看到显著的性能提升,因为网络规模相对较小。
以下是使用 SimpleChains.jl 进行训练的 Julia 代码
using SimpleChains, MLDatasets
lenet = SimpleChain(
(static(28), static(28), static(1)),
SimpleChains.Conv(SimpleChains.relu, (5, 5), 6),
SimpleChains.MaxPool(2, 2),
SimpleChains.Conv(SimpleChains.relu, (5, 5), 16),
SimpleChains.MaxPool(2, 2),
Flatten(3),
TurboDense(SimpleChains.relu, 120),
TurboDense(SimpleChains.relu, 84),
TurboDense(identity, 10),
)
# 3d and 0-indexed
xtrain3, ytrain0 = MLDatasets.MNIST.traindata(Float32);
xtest3, ytest0 = MLDatasets.MNIST.testdata(Float32);
xtrain4 = reshape(xtrain3, 28, 28, 1, :);
xtest4 = reshape(xtest3, 28, 28, 1, :);
ytrain1 = UInt32.(ytrain0 .+ 1);
ytest1 = UInt32.(ytest0 .+ 1);
lenetloss = SimpleChains.add_loss(lenet, LogitCrossEntropyLoss(ytrain1));
# initialize parameters
@time p = SimpleChains.init_params(lenet);
# initialize a gradient buffer matrix; number of columns places an upper bound
# on the number of threads used.
G = similar(p, length(p), min(Threads.nthreads(), (Sys.CPU_THREADS ÷ ((Sys.ARCH === :x86_64) + 1))));
# train
@time SimpleChains.train_batched!(G, p, lenetloss, xtrain4, SimpleChains.ADAM(3e-4), 10);
SimpleChains.accuracy_and_loss(lenetloss, xtrain4, p)
SimpleChains.accuracy_and_loss(lenetloss, xtest4, ytest1, p)
# train without additional memory allocations
@time SimpleChains.train_batched!(G, p, lenetloss, xtrain4, SimpleChains.ADAM(3e-4), 10);
# assess training and test loss
SimpleChains.accuracy_and_loss(lenetloss, xtrain4, p)
SimpleChains.accuracy_and_loss(lenetloss, xtest4, ytest1, p)PyTorch
在我们展示结果之前,让我们看看竞争对手。以下是使用 PyTorch 在 A100 GPU 上运行 10 个 epoch 的两次运行结果,使用的是 此脚本,批次大小为 2048
A100
Took: 17.66
Accuracy: 0.9491
Took: 17.62
Accuracy: 0.9692尝试使用 V100
Took: 16.29
Accuracy: 0.9560
Took: 15.94
Accuracy: 0.9749这个问题太小了,无法饱和 GPU,即使使用这么大的批次大小。时间主要消耗在将批次从 CPU 移动到 GPU 上。不幸的是,随着批次大小的增加,我们需要更多 epochs 才能达到相同的精度,因此我们在最大化精度/时间方面会遇到限制。
使用 AMD EPYC 7513 32 核处理器的 PyTorch
Took: 14.86
Accuracy: 0.9626
Took: 15.09
Accuracy: 0.9783使用 Intel i9 10980XE 18 核处理器的 PyTorch
Took: 11.24
Accuracy: 0.9759
Took: 10.78
Accuracy: 0.9841Flux.jl
Julia 中标准的机器学习库,Flux.jl 使用 此脚本 在 A100 GPU 上进行了基准测试。速度怎么样?
julia> @time train!(model, train_loader)
74.678251 seconds (195.36 M allocations: 12.035 GiB, 4.28% gc time, 77.57% compilation time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((loss = 0.1579f0, acc = 95.3583), (loss = 0.1495f0, acc = 95.54))
julia> @time train!(model, train_loader)
1.676934 seconds (1.04 M allocations: 1.840 GiB, 5.64% gc time, 0.63% compilation time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((loss = 0.0819f0, acc = 97.4967), (loss = 0.076f0, acc = 97.6))在 V100 GPU 上运行的 Flux
julia> @time train!(model, train_loader)
75.266441 seconds (195.52 M allocations: 12.046 GiB, 4.02% gc time, 74.83% compilation time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((loss = 0.1441f0, acc = 95.7883), (loss = 0.1325f0, acc = 96.04))
julia> @time train!(model, train_loader)
2.309766 seconds (1.06 M allocations: 1.841 GiB, 2.87% gc time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((loss = 0.0798f0, acc = 97.5867), (loss = 0.0745f0, acc = 97.53))在 AMD EPYC 7513 32 核处理器上运行的 Flux
julia> @time train!(model, train_loader)
110.816088 seconds (70.82 M allocations: 67.300 GiB, 4.46% gc time, 29.13% compilation time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((acc = 93.8667, loss = 0.213f0), (acc = 94.26, loss = 0.1928f0))
julia> @time train!(model, train_loader)
74.710972 seconds (267.64 k allocations: 62.860 GiB, 3.65% gc time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((acc = 96.7117, loss = 0.1121f0), (acc = 96.92, loss = 0.0998f0))在 Intel i9 10980XE 18 核处理器上运行的 Flux
julia> @time train!(model, train_loader)
72.472941 seconds (97.92 M allocations: 67.853 GiB, 3.51% gc time, 38.08% compilation time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((acc = 95.56, loss = 0.1502f0), (acc = 95.9, loss = 0.1353f0))
julia> @time train!(model, train_loader)
45.083632 seconds (348.19 k allocations: 62.864 GiB, 2.77% gc time)
julia> eval_loss_accuracy(train_loader, model, device),
eval_loss_accuracy(test_loader, model, device)
((acc = 97.5417, loss = 0.082f0), (acc = 97.74, loss = 0.0716f0))SimpleChains.jl 花了多长时间?
在 AMD EPYC 7513 32 核处理器上运行的 SimpleChains
#Compile
julia> @time SimpleChains.train_batched!(G, p, lenetloss, xtrain4, SimpleChains.ADAM(3e-4), 10);
34.410432 seconds (55.84 M allocations: 5.920 GiB, 3.79% gc time, 85.95% compilation time)
julia> SimpleChains.error_mean_and_loss(lenetloss, xtrain4, p)
(0.972, 0.093898475f0)
julia> SimpleChains.error_mean_and_loss(lenetloss, xtest4, ytest1, p)
(0.9744, 0.08624289f0)
julia> @time SimpleChains.train_batched!(G, p, lenetloss, xtrain4, SimpleChains.ADAM(3e-4), 10);
3.083624 seconds
julia> SimpleChains.error_mean_and_loss(lenetloss, xtrain4, p)
(0.9835666666666667, 0.056287352f0)
julia> SimpleChains.error_mean_and_loss(lenetloss, xtest4, ytest1, p)
(0.9831, 0.053463124f0)在 Intel i9 10980XE 18 核处理器上运行的 SimpleChains
#Compile
julia> @time SimpleChains.train_batched!(G, p, lenetloss, xtrain4, SimpleChains.ADAM(3e-4), 10);
35.578124 seconds (86.34 M allocations: 5.554 GiB, 3.94% gc time, 95.48% compilation time)
julia> SimpleChains.accuracy_and_loss(lenetloss, xtrain4, p)
(0.9697833333333333, 0.10566422f0)
julia> SimpleChains.accuracy_and_loss(lenetloss, xtest4, ytest1, p)
(0.9703, 0.095336154f0)
julia> # train without additional memory allocations
@time SimpleChains.train_batched!(G, p, lenetloss, xtrain4, SimpleChains.ADAM(3e-4), 10);
1.241958 seconds
julia> # assess training and test loss
SimpleChains.accuracy_and_loss(lenetloss, xtrain4, p)
(0.9801333333333333, 0.06850684f0)
julia> SimpleChains.accuracy_and_loss(lenetloss, xtest4, ytest1, p)
(0.9792, 0.06557372f0)
julia> # train without additional memory allocations
@time SimpleChains.train_batched!(G, p, lenetloss, xtrain4, SimpleChains.ADAM(3e-4), 10);
1.230244 seconds
julia> # assess training and test loss
SimpleChains.accuracy_and_loss(lenetloss, xtrain4, p)
(0.9851666666666666, 0.051207382f0)
julia> SimpleChains.accuracy_and_loss(lenetloss, xtest4, ytest1, p)
(0.982, 0.05452118f0)在 Intel i7 1165G7 4 核处理器(轻薄笔记本电脑 CPU)上运行的 SimpleChains
#Compile
julia> @time SimpleChains.train_batched!(G, p, lenetloss, xtrain, SimpleChains.ADAM(3e-4), 10);
41.053800 seconds (104.10 M allocations: 5.263 GiB, 2.83% gc time, 77.62% compilation time)
julia> SimpleChains.accuracy_and_loss(lenetloss, xtrain, p),
SimpleChains.accuracy_and_loss(lenetloss, xtest, ytest, p)
((0.9491333333333334, 0.16993132f0), (0.9508, 0.15890576f0))
julia> @time SimpleChains.train_batched!(G, p, lenetloss, xtrain, SimpleChains.ADAM(3e-4), 10);
5.320512 seconds
julia> SimpleChains.accuracy_and_loss(lenetloss, xtrain, p),
SimpleChains.accuracy_and_loss(lenetloss, xtest, ytest, p)
((0.9700833333333333, 0.10100537f0), (0.9689, 0.09761506f0))请注意,较小的批次大小可以提高每个 epoch 的精度,批次大小被设置为与线程数成比例。
基准测试摘要
第一个 epoch 开始训练之前的延迟是一个问题,但 SimpleChains.jl 在编译完成后速度很快。编译后,10980XE 与使用 A100 GPU 的 Flux 相当,比 V100 快约 35%。1165G7 是一款配备 AVX512 的笔记本电脑 CPU,表现出色,轻松超越了在更强大的 CPU 上运行的任何竞争机器学习库,甚至超过了 V100 和 A100 上运行的 PyTorch。再次强调,这个测试用例遵循了更典型的机器学习使用方式,因此能够使用批处理,甚至让 GPU 可行:对于 SimpleChains.jl 的许多用例来说,情况并非如此,因此差异更大。
然而,PyTorch 脚本似乎没有针对 GPU 进行良好的优化;我们对 PyTorch 的了解不多,欢迎您提出改进它的 PR。也就是说,该脚本来自现实世界的用户,因此应该能够展示那些没有深入研究内部细节和超参数优化的用户所期望的结果。Julia 脚本没有进行任何特别的操作:这些都是“按部就班”的实现。当然,SimpleChains.jl 最简单的代码专门针对这种“按部就班”的用例进行了优化。
结论
许多因素可以使一个库实现高性能,没有什么比了解它的用途更重要了。虽然大型机器学习框架在为 99.9% 的用户提供顶级性能方面做得非常好,但当专注于 0.1% 处于它们目标范围之外的应用时,仍然可以完全超越它们。这就是可组合性和灵活性的优势:一种允许您轻松构建机器学习框架的语言,也是一种允许您构建针对其他用户优化的替代框架的语言。SimpleChains.jl 并非对每个人都有用,但对于需要它的人来说将非常有用。