你好,世界!
在这篇文章中,我将简要总结一下我在今年夏天为 GSoC 开发的机器学习模型。我致力于丰富 Flux.jl 的模型库,Flux.jl 是用 Julia 编写的机器学习库。我的项目涵盖了强化学习和计算机视觉模型。
该项目分布在这 4 个代码库中
在此过程中,我实现了大多数目标。我不得不跳过其中几个,还做了一些计划外的模型。下面,我将根据这些问题进行仓库层级的讨论。
Flux Baselines
Flux Baselines
Flux-baselines 是一个包含各种深度强化学习模型的集合。这包括深度 Q 网络、Actor-Critic 和 DDPG。
RL 问题的基本结构如下:有一个环境,比如我们环境中的乒乓球游戏。环境可能包含许多相互作用的对象。在乒乓球游戏中,有 3 个对象:一个球和 2 个球拍。环境具有一个状态。它指的是环境中当前存在的情况,包括其中对象的各种特征。这些特征可以是位置、速度、颜色等,涉及其中的对象。需要选择一个动作来在环境中执行一个移动并获得下一个状态。将不断选择动作,直到游戏结束。RL 模型基本上找到需要选择的动作。
在过去的几年中,深度 Q 学习获得了极大的普及。Deep Mind 关于使用强化学习进行人类水平控制的论文发表后,人们就再也无法回头了。它将 RL 和深度学习的进步结合起来,获得了具有超人类性能的 AI 玩家。我在 GSoC 前期阶段完成了基本的 DQN 和 Double DQN,随后在 GSoC 的第一周完成了 Duel DQN。
A2C 模型 中使用的想法不同于 DQN 中的。A2C 属于“Actor-Critic”模型类别。在 AC 模型中,我们有两个神经网络:策略网络和价值网络。策略网络接收游戏的状态,并返回动作空间上的概率分布。价值网络以策略网络选择的动作和状态作为输入,并确定该动作对于该状态的合适程度。
DDPG 在需要选择的动作分布在连续空间中的情况下特别有用。您可能想到的一个可能的解决方案是,如果我们离散化动作空间会怎么样?如果我们狭隘地离散化它,我们最终会得到大量的动作。如果我们稀疏地离散化它,那么我们会丢失重要的数据。
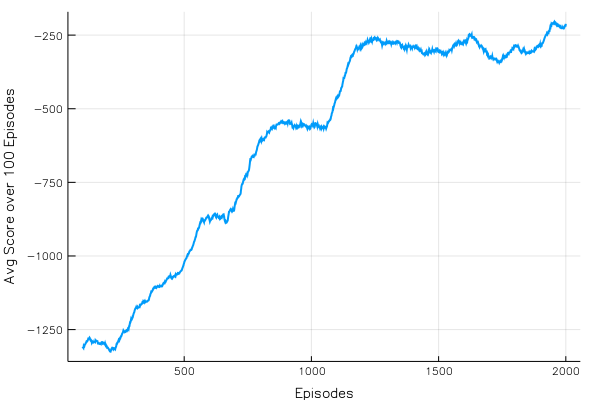
DDPG:分数 vs. 集数
其中一些模型已经部署在 Flux 的 网站 上。 CartPole 示例 是使用深度 Q 网络训练的。几天后还会添加一个 Atari-Pong 示例。它使用 Duel-DQN 训练。 这里 是使用 Flux 训练的 Pong 的演示。
已实现的目标
额外里程
未来工作
添加更多种类的模型,特别是过去 18 个月出现的那些模型。
创建一个界面,以便轻松地从 OpenAIGym.jl 中训练和测试任何环境。
AlphaGo.jl
AlphaGo.jl
GSoC 第 2 阶段的这个小型项目是最具挑战性的部分。AlphaGo Zero 是 Google DeepMind 的一个突破性的 AI。它是一个玩围棋的 AI,围棋被认为是世界上最具挑战性的游戏之一,主要是因为它可以产生的状态数量。AlphaGo Zero 击败了世界上最优秀的围棋选手。AlphaFo.jl 的目标是在围棋上实现 AlphaGo Zero 算法产生的结果,并在任何零和游戏中实现类似的结果。
现在,我们有一个包可以在 Julia 中训练 AlphaGo Zero 模型!并且训练模型真的很简单。我们只需要传入训练参数、我们要训练模型的环境,然后就可以玩了。有关 AlphaGo.jl 的更多信息,请参阅 博客文章。
已实现的目标
围棋
蒙特卡洛树搜索
无法实现的目标
无法很好地训练模型
额外里程
玩五子棋来测试算法(因为它是更简单的游戏)
未来工作
在任何游戏中训练模型
AlphaChess
生成对抗网络
生成对抗网络
GAN 在学习任何数据的底层表示方面非常成功。通过这样做,它可以生成一些假数据。例如,在 MNIST 手写数字数据集上训练的 GAN 可以生成一些看起来非常像 MNIST 中那些的假图像。这些神经网络在图像编辑方面具有很大的应用。它可以从图像中删除某些特征,添加一些新的特征;这取决于数据集。GAN 包含两个网络:生成器和鉴别器。生成器的目标是生成假图像,而鉴别器的目标是区分生成器生成的假图像和数据集中真实图像。




LSGAN DCGAN WGAN MADE
已实现的目标
额外里程
未来工作
更多 GAN 模型,例如 infoGAN、BEGAN、CycleGAN
使用 GAN 制作的一些酷炫动画
用于训练和生成图像的数据管道,以数据集和 GAN 类型作为输入。
解耦神经接口
解耦神经接口
解耦神经接口 是一种新的模型训练技术。它不使用从输出层一直到输入层的反向传播。而是使用一个“估计”梯度的技巧。它有一个小的线性层神经网络来预测梯度,而不是运行反向传播而是找到真正的梯度。这种模型的优点是可以并行化。这种技术会导致精度略有下降,但如果我们将网络中的层并行化,那么我们可以提高速度。
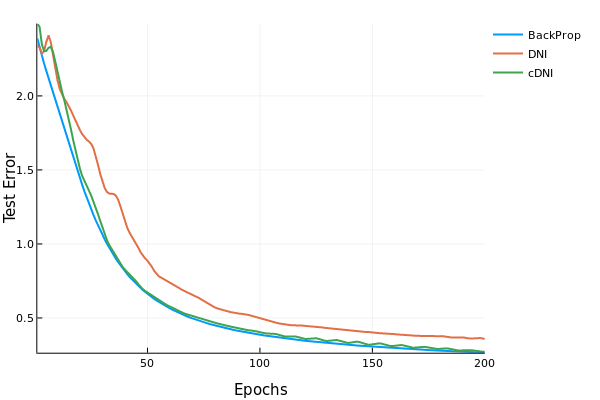
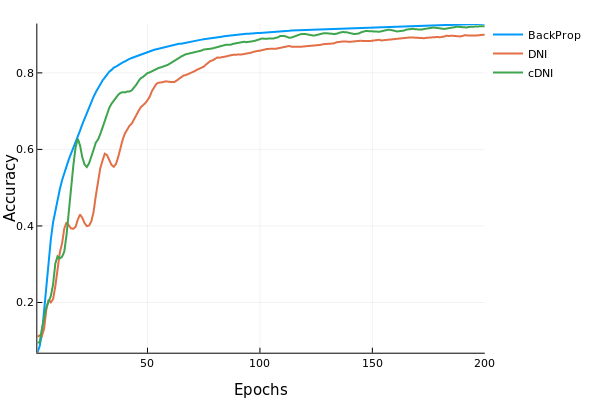
已实现的目标
结论
在过去三个月中,我对强化学习,特别是 AlphaGo 有了深入的了解。我体验了训练 RL 模型数天,最终看到它运行良好!我遇到了训练模型中遇到的问题,并学会了克服这些问题。总而言之,作为一名有抱负的机器学习工程师,这三个月是我最有成效的三个月。我很高兴我能够实现大多数目标。我开发了一些额外的模型来弥补我无法实现的目标。
鸣谢
我要真诚地感谢我的导师 Mike Innes 在整个项目中对我进行指导,以及 James Bradbury 为改进强化学习模型中的代码提供的宝贵建议。我还要感谢 Neethu Mariya Joy 将训练好的模型部署到网络上。最后但并非最不重要的是,Julia 项目和 NumFOCUS:赞助我以及所有参加 JuliaCon'18 伦敦的 JSoC 学生。