我在 2015 年 Julia暑期代码 计划中的项目是开发 NullableArrays 包,该包提供了 NullableArray 数据类型及其相应的接口。我今年早些时候第一次接触 Julia,当时有人建议我作为一名即将入学的统计学博士生应该学习哪种语言。今年夏天对我来说是一个难以置信的机会,我既可以作为一名年轻的程序员发展自己,也可以为像 Julia 这样充满潜力的开源社区做出贡献。我不能不感谢 Alan Edelman 在 MIT 的小组、NumFocus 和 Gordon & Betty Moore 基金会 的财务支持,感谢 John Myles White 的指导和帮助,以及 Julia 社区的许多其他成员,他们在整个夏天都帮助为该包做出了贡献,并帮助我提高了编程能力。我在这项项目上的大部分工作都是在 Recurse Center 进行的,在那里我得到了一个由令人惊叹的自学型学习者组成的社区的支持。
NullableArray 数据结构
NullableArray 是数组结构,可以有效地表示缺失值,而不会遇到 DataArray 对象面临的性能问题,DataArray 对象迄今为止一直用于存储包含缺失值的数据。导致 DataArray 性能下降的核心问题在于前者表示缺失值的方式,即通过 NAType 类型标记 NA 对象。特别是,索引到例如 DataArray{Int} 中可能会返回类型为 Int 或类型为 NAType 的对象。这种设计没有为 Julia 的类型推断系统在 JIT 编译时提供足够的信息来支持 Julia 编译器可以利用的其他静态分析来生成高效的机器代码。我们可以通过以下示例来说明这一点,在该示例中,我们计算存储在 DataArray 中的五百万个随机 Float64 的总和。
julia> using DataArrays
# warnings suppressed…
julia> A = rand(5_000_000);
julia> D = DataArray(A);
julia> function f(D::AbstractArray)
x = 0.0
for i in eachindex(D)
x += D[i]
end
x
end
f (generic function with 1 method)
julia> f(D);
julia> @time f(D)
0.163567 seconds (10.00 M allocations: 152.598 MB, 9.21% gc time)
2.500102419334644e6遍历并对 D 的元素求和的速度要慢 20 多倍,并且分配的内存也比对 A 运行相同循环多得多。
julia> f(A);
julia> @time f(A)
0.007465 seconds (5 allocations: 176 bytes)
2.500102419334644e6这是因为为 f(D) 生成的代码必须假设对于任意索引 i,getindex(D, i) 可能会返回类型为 Float64 或类型为 NAType 的对象,因此必须“封装”从索引到 D 中返回的每个对象。此要求带来的性能损失反映在上述比较中。(感兴趣的读者可以找到更多关于这些问题的信息 这里。)
另一方面,NullableArray 旨在支持 Julia 的类型推断系统用于生成高效机器代码的静态分析。该策略的关键是使用单个类型——Nullable{T}——来表示缺失值和存在值。Nullable{T} 对象是专门的容器,可以精确地保存一个或零个值。一个封装例如 5 的 Nullable 可以被认为表示存在值为 5,而一个空的 Nullable{Int} 可以表示一个缺失值,如果该值存在,则其类型将为 Int。至关重要的是,这两个对象都是相同的类型,即 Nullable{Int}。感兴趣的读者可以在我的 JuliaCon 2015 简短演讲 中听到更多关于这些设计考虑的信息。
以下是对可比的 NullableArray 运行相同循环的结果
julia> using NullableArrays
julia> X = NullableArray(A);
julia> function f(X::NullableArray)
x = Nullable(0.0)
for i in eachindex(X)
x += X[i]
end
x
end
f (generic function with 1 method)
julia> f(X);
julia> @time f(X)
0.009812 seconds (5 allocations: 192 bytes)
Nullable(2.500102419334644e6)可以看出,在时间和内存分配方面,天真地遍历 NullableArray 与天真地遍历常规 Array 的数量级相同。下面是一组图(使用 Gadfly.jl 绘制),这些图可视化了对 NullableArray 和 DataArray 参数分别运行 20 个基准样本 f 的结果,每个参数都包含 5,000,000 个随机 Float64 值,并且包含零个空条目或大约一半随机选择的空条目。
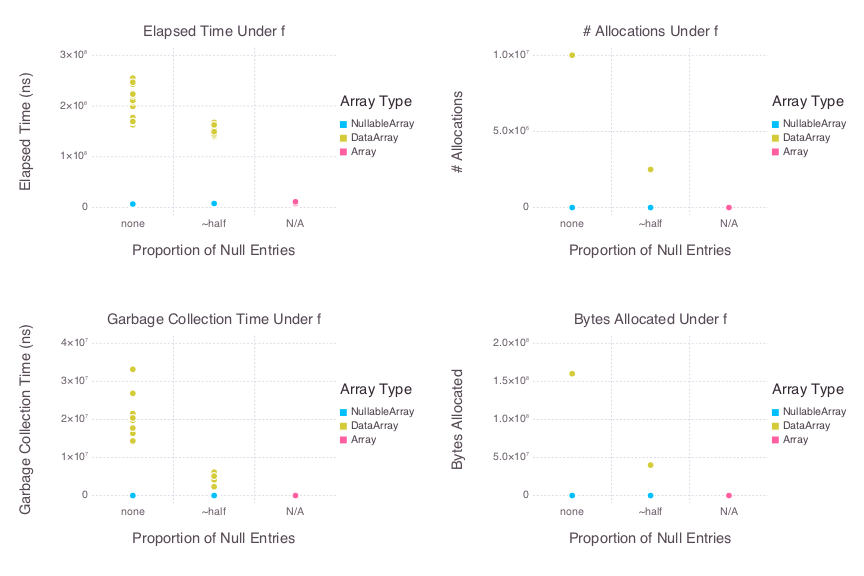
当然,可以将此类循环在 DataArray 上的性能提高到与在 Array 上的循环相当的水平。但是,此类优化通常会引入额外的复杂性,而这些复杂性本不应该在执行如此简单的任务时需要。在更复杂的实现中(例如 broadcast! 的实现)可能需要更复杂的代码来实现性能。我们希望 NullableArray 在涉及缺失数据的复杂任务中表现良好,同时尽可能减少与 NullableArray 内部交互。这包括允许用户利用现有的实现而不会牺牲性能。例如,考虑依赖 Base 对 DataArray 和 NullableArray 参数实现 broadcast! 的结果(即,已从每个包的源代码中省略了相应的 src/broadcast.jl)。以下是可视化运行 20 个基准样本 broadcast!(dest, src1, src2) 结果的图,其中 dest 和 src2 是 5_000_000 x 2 的 Array、NullableArray 或 DataArray,而 src1 是 5_000_000 x 1 的 Array、NullableArray 或 DataArray。与上面一样,NullableArray 和 DataArray 参数在零个或大约一半空条目的情况下进行测试。

我们设计了 NullableArray 类型,使其尽可能像常规 Array 一样。但是,NullableArray 返回 Nullable 对象与 Array 和 DataArray 的行为有很大不同。可以说,最重要的问题是支持用户定义的函数,这些函数在与 Nullable 和 NullableArray 对象交互时缺乏 Nullable 参数的方法。在我的项目中,我还致力于开发使处理 Nullable 对象变得用户友好和安全的接口。
给定一个在类型 (U1, U2, …, UN) 的参数签名上定义的方法 f,我们希望为用户提供一种易于访问、安全且高效的方式来在类型 (Nullable{U1}, Nullable{U2}, …, Nullable{UN}) 的参数签名上调用 f,而无需用户自己扩展 f。这样做应该返回 Nullable(f(get(u1), get(u1), …, get(un))),如果每个参数都不为空,并且如果任何参数为空,则应返回一个空的 Nullable。系统地扩展任意方法 f 以覆盖 Nullable 参数签名通常称为在 Nullable 参数上“提升” f。
NullableArrays 为某些方法(例如 broadcast 和 map)提供关键字参数,这些参数指示后者方法在 NullableArray 参数上提升传递的函数参数。
julia> X = NullableArray(collect(1:10), rand(Bool, 10))
10-element NullableArray{Int64,1}:
#NULL
#NULL
#NULL
4
5
6
7
8
#NULL
10
julia> f(x::Int) = 2x
f (generic function with 2 methods)
julia> map(f, X)
ERROR: MethodError: `f` has no method matching f(::Nullable{Int64})
Closest candidates are:
f(::Any, ::Any)
[inlined code] from /Users/David/.julia/v0.4/NullableArrays/src/map.jl:93
in _F_ at /Users/David/.julia/v0.4/NullableArrays/src/map.jl:124
in map at /Users/David/.julia/v0.4/NullableArrays/src/map.jl:172
julia> map(f, X; lift=true)
10-element NullableArray{Int64,1}:
#NULL
#NULL
#NULL
8
10
12
14
16
#NULL
20我还计划很快发布一个小包,该包将提供一个更灵活的“提升”宏,该宏将能够在各种表达式类型中在 Nullable 参数上提升函数调用。
我们希望新的 NullableArrays 包不仅能帮助支持 Julia 的统计计算生态系统向前发展,还能支持任何需要高效、完善的接口来处理 Nullable 对象数组的努力。请尝试使用该包,提交功能请求、报告错误,如果您有兴趣,请提交一个或两个 PR。编码愉快!